鼻歌が楽譜に!Python Webアプリ開発で遭遇した5つの壁とその乗り越え方
August 17, 2025 development notes Python Webアプリ Hugging Face Gunicorn librosa

こんにちは!今回は、私が開発したWebアプリケーション「HanautaMelody(ハナウタメロディー)」の開発過程で直面した、リアルな問題解決の道のりを共有したいと思います。このアプリは、ユーザーがハミングしたメロディーをリアルタイムで解析し、楽譜として表示するものです。 ローカル環境では完璧に動いていたのに、Hugging Face Spacesにデプロイした途端、次々と問題が発生しました。この記事が、同じような壁にぶつかっている開発者の助けになれば幸いです。
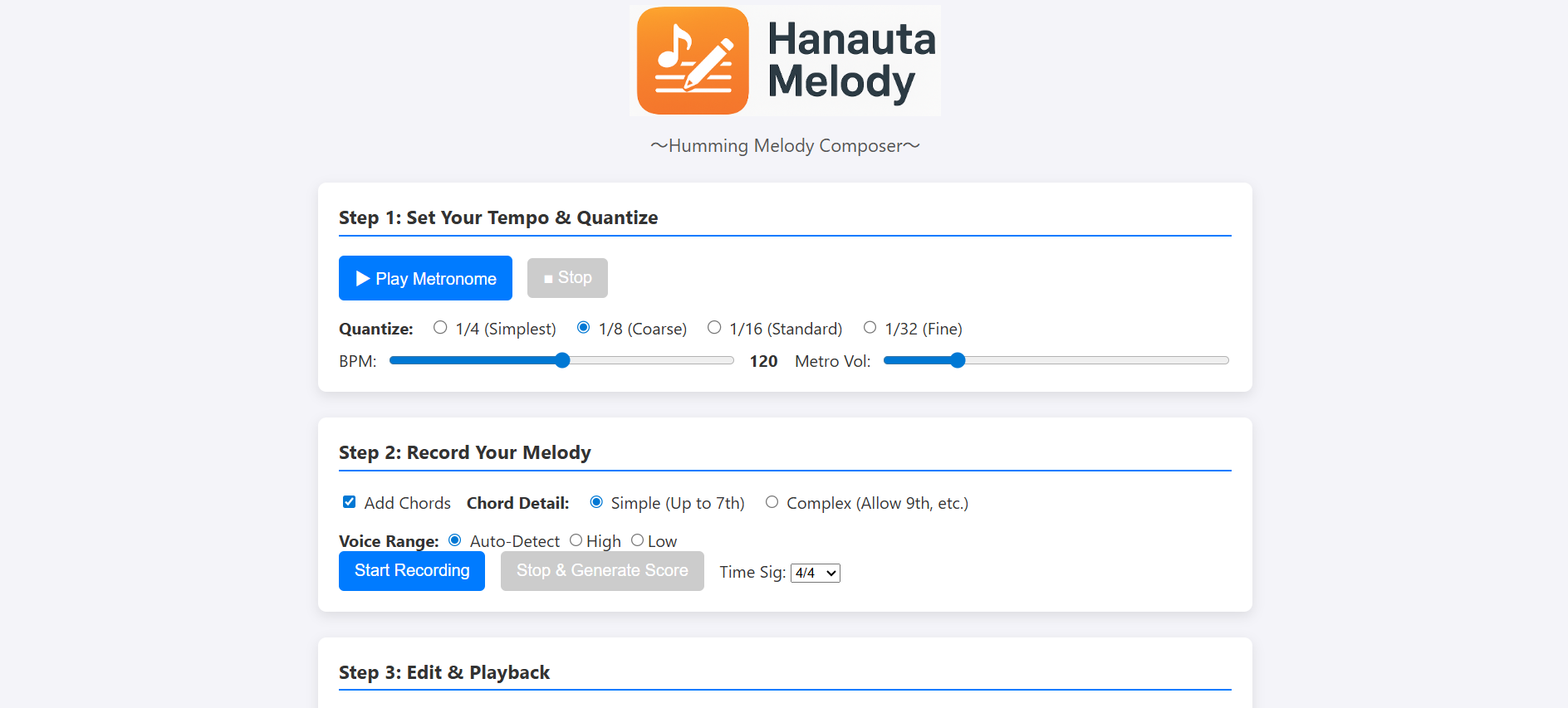
壁1:サーバーが起動しない!謎の「沈黙クラッシュ」
最初に直面したのは、最も不可解な問題でした。デプロイ後、アプリのログを見るとGunicorn(Webサーバー)が起動しようとするものの、数行のログを残して沈黙。エラーメッセージすら表示されずにコンテナが再起動を繰り返すのです。
仮説と調査:
最初はGunicornの設定か、Dockerfileの記述ミスを疑いました。しかし、設定はごく標準的です。次に疑ったのは、librosaやmusic21といった、重いライブラリの読み込みです。特に音声や音楽を扱うライブラリは、内部でC言語などで書かれたシステムライブラリを必要とすることがあります。
解決策:
調査の結果、librosaが内部で利用するsoundfileライブラリが、システムライブラリlibsndfile1を必要としていることが判明しました。また、Hugging Faceの無料コンテナは起動時間に制限があるため、ライブラリの初回読み込みに時間がかかりすぎてタイムアウトしている可能性も浮上しました。
そこで、Dockerfileを以下のように修正しました。
# 修正前
RUN apt-get update && apt-get install -y --no-install-recommends ffmpeg && rm -rf /var/lib/apt/lists/*
# 修正後
RUN apt-get update && apt-get install -y --no-install-recommends \
ffmpeg \
libsndfile1 \
# soundfileライブラリに必要なシステム依存関係を追加
&& rm -rf /var/lib/apt/lists/*
# Gunicornの起動コマンドにもタイムアウト延長オプションを追加
CMD ["gunicorn", "app:app", "--bind", "0.0.0.0:8000", "--timeout", "600"] # ※(8000のところは個別に要変更)
この修正により、サーバーは無事に起動するようになりました。教訓:クラウド環境での動作不良は、まずシステムライブラリの不足を疑うべし。
壁2:音声ファイルをアップロードした瞬間にクラッシュ
サーバーは起動しましたが、安心したのも束の間。録音した音声ファイルをサーバーに送信(/analyze)した瞬間に、またしてもサーバーが応答しなくなりました。
仮説と調査:
ログを見ると、リクエスト自体はサーバーに届いています。しかし、Flaskのprint()文が一つも実行される前にクラッシュしていることから、音声ファイルを処理するpydubライブラリの非常に初期の段階で問題が起きていると推測しました。pydubがメモリ上のオーディオストリームをコンテナ環境でうまく扱えていない可能性がありました。
解決策:
メモリ上で直接処理するのをやめ、より堅牢な方法に切り替えました。アップロードされた音声ファイルを、一度サーバーの一時ファイルとしてディスクに保存し、そのファイルパスをpydubに渡して読み込ませる方式です。
# app.py
import tempfile
import os
# ...
@app.route('/analyze', methods=['POST'])
def analyze():
file = request.files['audio_data']
# 一時ディレクトリとファイルパスを作成
temp_dir = tempfile.mkdtemp()
temp_audio_path = os.path.join(temp_dir, 'uploaded_audio.wav')
file.save(temp_audio_path) # 一度ディスクに保存
try:
# ファイルパスから安全に読み込み
audio = AudioSegment.from_file(temp_audio_path)
# ... (音声処理)
finally:
# 処理が終わったら必ず一時ファイルを削除
os.remove(temp_audio_path)
os.rmdir(temp_dir)
# ... (以降の処理)
この修正で、音声解析プロセスが安定して動作するようになりました。教訓:ライブラリが不安定な動作をするときは、一度ディスクを介す昔ながらの方法が有効なことがある。
壁3:精度と速度のトレードオフ、そして改善策
当初、このアプリはGoogle製の高精度なピッチ検出モデルcrepeを使う予定でした。しかし、このモデルは非常に重く、無料環境ではリソース不足でほぼ確実にクラッシュします。
解決策:
そこで、軽量かつ高速な信号処理ベースのアルゴリズムであるlibrosa.pyinに切り替えました。これにより解析速度は3秒程度まで劇的に向上しましたが、代わりに精度が若干犠牲になりました(特にオクターブ間違いなど)。
この精度を少しでも向上させるため、ユーザーにヒントを与えてもらう機能を実装しました。
- UIに「声域(Voice Range)」の選択肢を追加:「男性/低め」「女性/高め」「自動」
- バックエンドで解析範囲を限定: ユーザーの選択に応じて、
librosa.pyinがピッチを探す周波数の範囲(fmin,fmax)を動的に変更します。
# app.py
voice_range = request.form.get('voice_range', 'auto')
if voice_range == 'female':
fmin = librosa.note_to_hz('F3')
fmax = librosa.note_to_hz('C6')
elif voice_range == 'male':
fmin = librosa.note_to_hz('C2')
fmax = librosa.note_to_hz('G4')
else: # auto
fmin = librosa.note_to_hz('C2')
fmax = librosa.note_to_hz('C7')
f0, voiced_flag, voiced_probs = librosa.pyin(y, fmin=fmin, fmax=fmax, sr=sr)
この小さな工夫で、アルゴリズムが倍音に惑わされるのを防ぎ、解析精度を大きく向上させることができました。教訓:最高のアルゴリズムが使えないなら、今あるアルゴリズムが働きやすいように人間が手助けするUIを作ればいい。
壁4:カスタムドメインとiframeの罠
Hugging Face Spacesのカスタムドメイン機能は有料プラン向けでした。そこで、Cloudflare Pagesなどの静的ホスティングサービスを使い、iframeでアプリを埋め込むという無料の回避策を取りました。しかし、これが新たな問題を生みました。
問題1:マイクが使えない!
iframeの中からマイクを使おうとすると、ブラウザのセキュリティ機能にブロックされ「Permission denied」エラーが発生。
解決策1:
iframeタグにallow="microphone"属性を追加し、親ページからiframe内のコンテンツへマイク使用権限を委譲しました。
<iframe src="https://my-username-hum-to-score.hf.space" allow="microphone"></iframe>
問題2:フッターのリンクがiframe内で開いてしまう
iframe内のフッターリンク(例: /privacy-policy)をクリックすると、iframeの中身だけが遷移しようとしてしまい、ページが見つからずエラーに。
解決策2:
<a>タグにtarget="_top"属性を追加し、ブラウザウィンドウ全体でページが開くように指示。また、URLもカスタムドメインを含む絶対パスに修正しました。
<a href="https://app.mydomain.com/privacy_policy.html" target="_top">Privacy Policy</a>
教訓:iframeのセキュリティとナビゲーションの仕様理解
壁5:データ型のバグ - Web開発永遠のテーマ
最後に遭遇したのは、Web開発者なら誰もが一度は通る道、データ型の問題です。
問題:
最初のメロディー解析は成功するのに、移調(Transpose)やMIDIエクスポートボタンを押すとTypeError: unsupported operand type(s) for /: 'int' and 'str'というエラーが発生。
原因:
最初の解析時、HTMLフォームから送られたBPM(テンポ)はint()で数値に変換していました。しかし、移調などの更新処理はJavaScriptのfetch API経由で行われ、JSONデータとして送られたBPMはPython側で文字列として解釈されていました。music21ライブラリがテンポ計算(割り算)をしようとして、数値と文字列の演算となりエラーになっていたのです。
解決策:
更新処理を受け取るAPIエンドポイント(/update_score, /update_midi)でも、BPMをきちんとint()で数値に変換しました。
# app.py
@app.route('/update_score', methods=['POST'])
def update_score():
data = request.json
# 文字列として受け取ったbpmを数値に変換する
bpm = int(data.get('bpm', 120))
# ...
教訓:外部から受け取るデータは、必ず期待するデータ型に変換・検証するべし。
まとめ
「HanautaMelody」の開発は、まさにデバッグと問題解決の連続でした。
- Dockerfileでのシステム依存関係の解決
- 不安定なライブラリのための一時ファイル処理
- アルゴリズムの限界をUIの工夫で補う発想
- iframeのセキュリティとナビゲーションの仕様理解
- そして、古典的だが重要なデータ型の検証
これらの壁を一つずつ乗り越えることで、アプリはより堅牢で実用的なものになりました。この開発ブログが、皆さんのプロジェクトの一助となれば幸いです。
ぜひ、皆さんも鼻歌を楽譜にしてみてください! HanautaMelodyを試してみる。